I am bad at taking notes, and I want to get better. There are two main obstacles that I face when I write down things that I want to remember.
Taking notes is inconvenient. I spend 90% of my work time in VSCode, either editing text or using the terminal, and using a note taking app requires me to context switch, load another application, and (worst of all) decide on where I’m going to store the note. Do I make another folder? Use a new note or an existing one?
Retrieving notes is hard. It’s common for me to have some “must remember” piece of information - maybe a code snippet for a common task, or a note from a meeting - and write it down on one of my many note-taking apps: Google Keep, Obsidian, Slack DM to self, etc. Then when I actually need the information later, I can’t remember where I put it. This gets really hard if I don’t remember when I wrote it, or what phrasing I used. Often, I find myself going through old notes by date, or searching some unrelated piece of information that I know I wrote down around the same time. If that fails, I sometimes look through old slack messages, emails, or my browser history trying to rediscover information. If I wrote it down on paper, there’s a high probability that the information is gone forever.
Recently, I resolved to start taking better notes, and decided to meet these challenges head on.
To tackle the first challenge, I started using an application called jrnl. Jrnl works from the command line and has good VSCode integration, so it fits into my existing workflow. For example, if I wanted to remember the right ratio of rice to water in my pressure cooker, I could write:
$ jrnl the right ratio of rice to water in a pressure cooker is 1-to-1.
I can read the contents of today’s entries in jrnl by writing:
$ jrnl -on today
┏━━━━━━━━━━━━━━━━━┓
┃ 1 entry found ┃
┗━━━━━━━━━━━━━━━━━┛
2023-12-23 07:48:22 PM the right ratio of rice to water in a pressure cooker is 1-to-1.
Jrnl is free, open-source, and extensible, so it’s compatible with my ethics as well!
To address my second concern, jrnl has several built-in ways to search for notes. You can search by date:
$ jrnl -to today # everything
$ jrnl -10 # last 10 entries
$ jrnl -from "last year" -to march # date range
You can also filter by tag. Use @ at the beginning of words to tag entries.
$ jrnl Use @python dataclasses to quickly create class constructors.
$ jrnl @python
┏━━━━━━━━━━━━━━━━━┓
┃ 1 entry found ┃
┗━━━━━━━━━━━━━━━━━┛
2023-12-25 02:54:41 PM Use @python dataclasses to quickly create class constructors.
You can also search for untagged text.
$ jrnl -contains dataclasses
┏━━━━━━━━━━━━━━━━━┓
┃ 1 entry found ┃
┗━━━━━━━━━━━━━━━━━┛
2023-12-25 02:54:41 PM Use @python dataclasses to quickly create class constructors.
This is pretty good - on par with other notetaking apps - but it can still be hard to retrieve the notes I want. In an app like Obsidian, I have a whole GUI which previews and lays out my notes, making it easier to retrieve information that I’m looking for. In jrnl, all I have is the command line. I would have to know ahead of time the exact wording or tags I used if I want to find a specific piece of information.
I had already decided I was done with Obsidian (and similar apps) precisely because I had to organize my notes when writing and saving them. I wanted to just take my thoughts (about anything) and throw them in a big bucket. To retrieve the notes effectively, I needed a better search strategy.
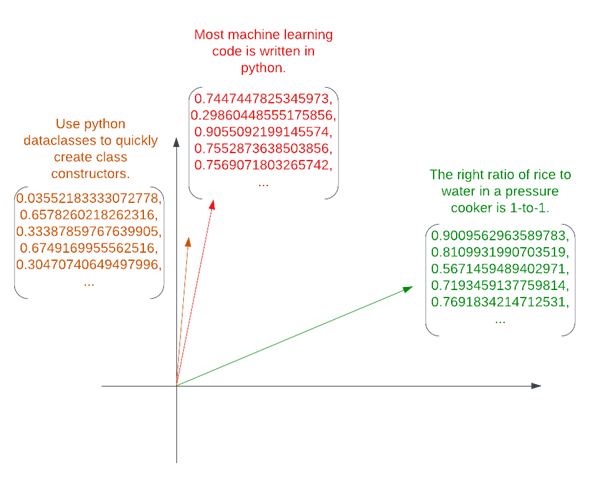
Semantic search is a way to search for text by meaning, rather than by directly matching words or phrases. This is more powerful than traditional keyword search because it can find synonyms or similarities which do not use the exact same words. Modern transformer models convert text to vector embeddings: a list of numbers which represents the meaning of the phrase. In transformer-based semantic search, a list of phrases or sentences is converted into a list of vector embeddings.
Three phrases embedded into a vector space. The vectors are embedded in 2-dimensional space in the image. In reality, hundreds of dimensions are typically used.
In the above image, vector embeddings have been generated for three phrases. Closer embeddings tend to be related. Transformer-based semantic search exploits this fact by embedding the search query, and then retrieving the entries closest to the query embedding.
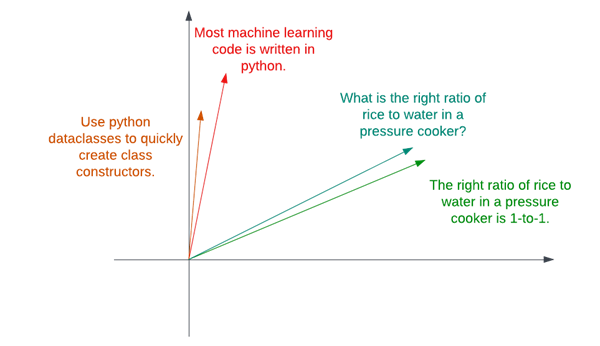
Crucially, it doesn’t matter if the question uses the exact same words, because embeddings of phrases with similar meanings are clustered closely, regardless of phrasing.
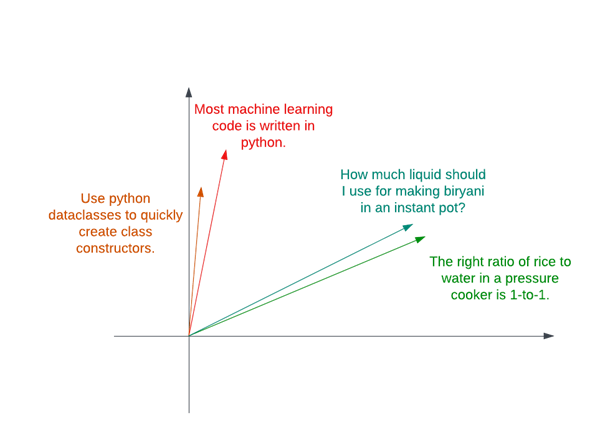
Finding the closest entry is usually straightforward. Three main similarity metrics can be used. The simplest is the actual distance between the vector tips, usually called the L2 norm. More commonly, the squared L2 norm is used, because it is easier to calculate and possesses some favorable qualities. The dot product is another common option, and is calculated by taking the of the products of corresponding elements of the vectors. Normalizing the dot product (dividing by vector length) gives the cosine similarity, a measure of the angle between the two vectors. All these similarity metrics lead to similar results, but they may perform better or worse depending on how the embedding models are trained.
Huggingface has a great python module for vector embeddings called Sentence Transformers, and a great tutorial on using this library to perform semantic search. Sentence Transformers offers support for many models, and a comparison page where they are evaluated against each other. Because of its top performance in semantic search, I decided to use multi-qa-mpnet-base-dot-v1.
Jrnl saves its entries in a text file separated by newlines. My library, which I called jrnl-search, collects the entries (using jrnl’s built-in methods) and embeds each one. The embeddings are saved as json, and each one is associated with an md5 hash of the original text prompt. This means that the prompt isn’t re-saved as plaintext, which would defeat the purpose of jrnl’s encryption option (this still is not secure, since the meaning of each entry can be approximately deduced from the embedding).
At runtime, jrnl-search first checks to see if all journal entries have embeddings by hashing each entry and comparing them to the list of keys in the embedding file. If any are missing, jrnl-search generates the embeddings and saves them to the embedding file.
When the user supplies a query, jrnl-search embeds that too, and finds the embedding’s dot product with each of the entry embeddings. It then sorts these by similarity and displays the results in order on a table. The table is rendered with rich and embedded in the native terminal’s pager using rich.console.Console.pager.
To improve execution speed, I made this process asynchronous using python’s asyncio library. Then I packaged the script with poetry and uploaded to Pypi. This means you can install it as a command line utility with pipx.
$ pipx install jrnl-search (this takes a while since it installs some beefy ML libraries).$ jrnl this entry is about bats$ jrnl this entry is not$ jrnl-search flying animals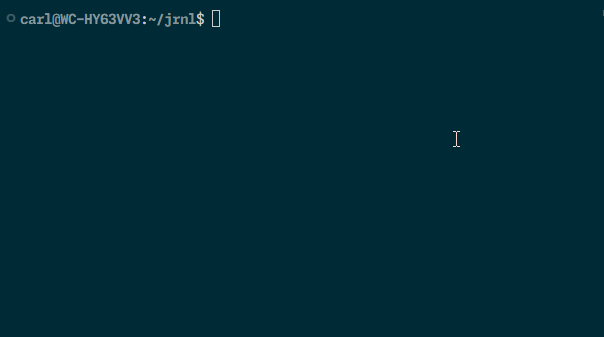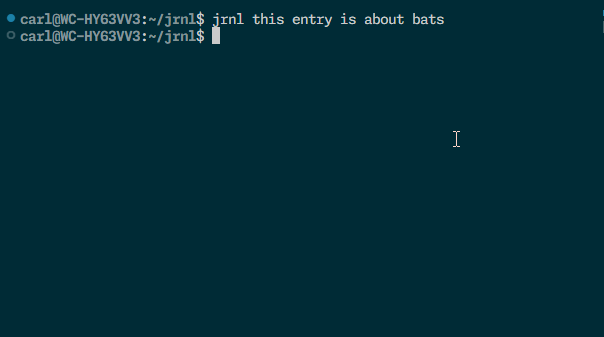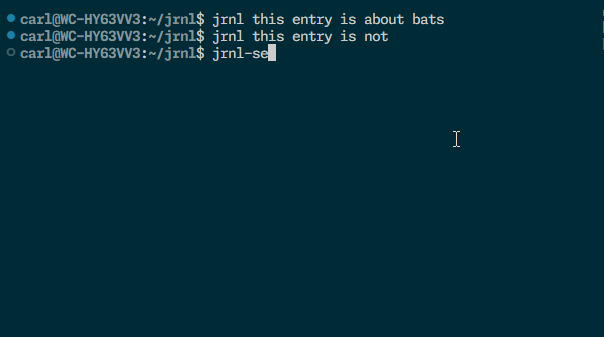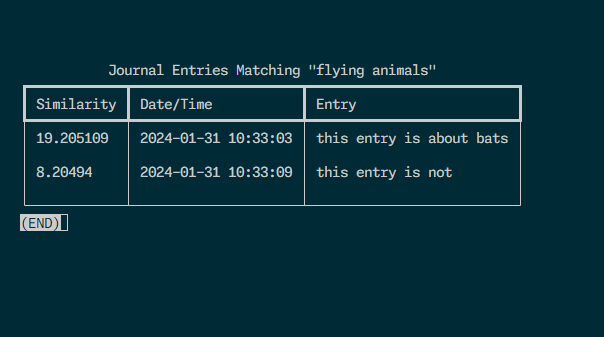
The current version of jrnl-search has a few limitations that I’d like to work on:
If you have suggestions or bugs, feel free to make an issue in the github repo or submit a PR!