
I’ve been spending the last month studying reinforcement learning. There are lots of great resources out there, and I’ve been focusing on Sutton and Barto and Spinning Up on Deep RL from OpenAI. Before this, I was only really familiar with supervised and unsupervised learning. I knew that reinforcement learning meant punishing or rewarding the computer, but that was basically it.
I also became a father this summer. My daughter, Florence, was born on July 23. She is a happy, healthy, beautiful girl, and watching her grow is satisfying in all the ways I expected, but also some I didn’t. While I’m reading about learning, I’m also watching something similar play out in real life, right in front of me.
Reinforcement learning has been a popular topic recently. Earlier this month, Dwarkesh Patel released an interview with Richard Sutton, the same guy who wrote the textbook I’m reading. Sutton also wrote the incredibly influential essay, “The Bitter Lesson”. In the interview, Sutton criticized OpenAI and others for trying to achieve artificial general intelligence (AGI) by scaling large language models (LLMs). Sutton’s main criticism is that LLMs do not learn from experience or work toward goals, and their knowledge is more akin to being taught what to say by a human tutor. He argues that we shouldn’t be surprised when this doesn’t lead to real intelligence, because “having a goal is the essence of intelligence”. Dwarkesh argues that, while pure supervised/unsupervised learning is unlikely to create AGI, LLMs can form a “scaffold or basis” on which RL can be used to make superintelligent AI. This also appears to be the position of the frontier labs, who are mostly focused on scaling up RL as the “fossil fuel” of training data is drying up. The interview triggered a lot of discussion online, maybe because both Sutton and Dwarkesh seemed a little combative. Dwarkesh even wrote a follow-up tweet in which he fully elaborated his opinion (and soft-apologized).
Predictably, Sutton and Dwarkesh discussed children a fair bit in the interview. Around minute 13, Dwarkesh claims that young children initially learn by imitation. Sutton disagrees, and says they learn by “just trying things”.
My sample size is 1, but I’ve been watching Florence closely since the day she was born. I think Sutton is much more right than Dwarkesh here, but something else is going on.
Florence has just started learning to grab things. She first tried it about a week ago, and now she has reached out, grabbed, and held things in front of me a couple times. Grabbing something requires a lot of coordination. You need to see that something is there. You need to know that it’s within reach. You need to move the right muscles to get your hand close to it (guided by your eyes). You need to open the hand, move it still closer, and close your fingers. How does she learn to do this? I think there are a couple possibilities.
The biggest argument against RL is that children require much less training than similar machine learning models. Take the cart pole problem, one of the simplest control problems.
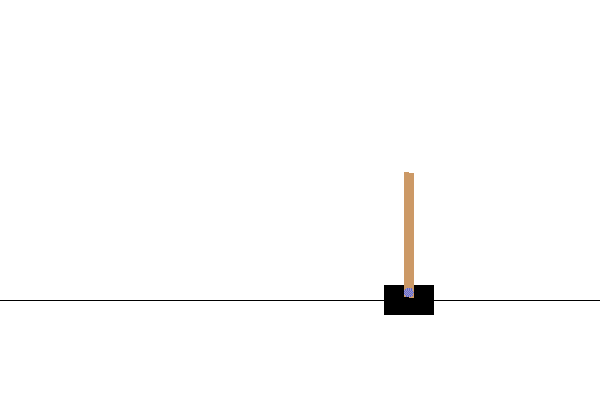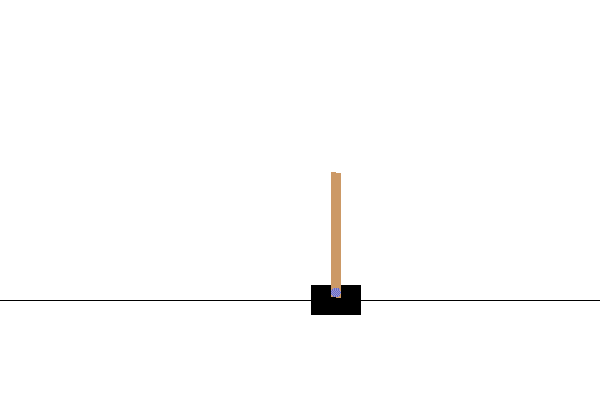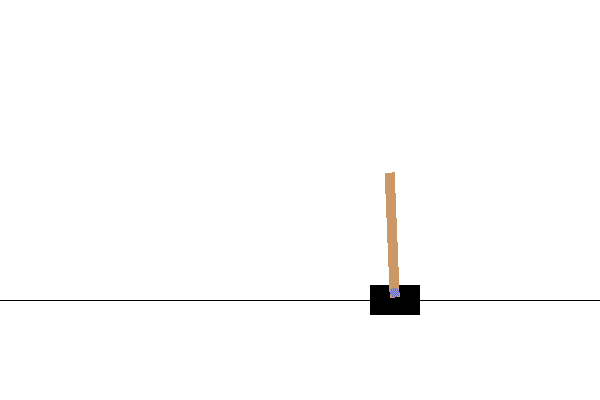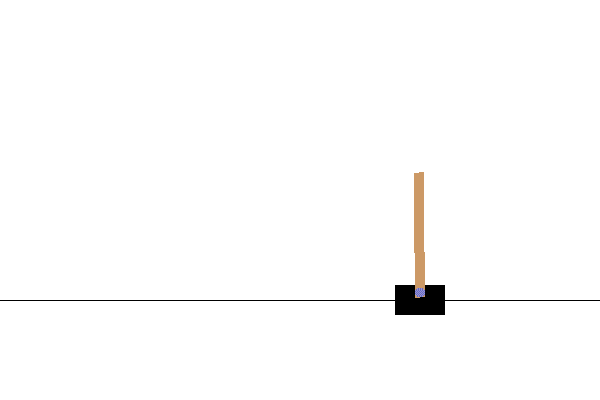 The object of the cart pole problem is to keep the inverted pendulum balanced by moving the cart along the track. Image from tensorflow.org.
The object of the cart pole problem is to keep the inverted pendulum balanced by moving the cart along the track. Image from tensorflow.org.
The cart has a single action dimension: the cart’s acceleration along the track. The observation space is also one-dimensional: the angle of the pole to the cart. Compare the action space to the hand, with at least 25 degrees of freedom1, and the human eye, with resolution measured in the hundreds of megapixels23. By a crude estimate, cart pole is a billion times simpler than grasping with a human hand.
Yet, when we try to use a RL algorithm to learn the solution to the cart pole problem, it takes about 500 tries. This is not a huge amount, but it’s more than you or I would need to learn to balance something. I’d estimate Florence took less than 100 tries to learn to grasp things, and certainly less than 500. In the computer’s early cart pole simulations, it does wildly incorrect things, but Florence’s early attempts to grasp at least seem deliberate.
When scientists attempt tasks of greater complexity, they often find that a lot more data is needed. For example, researchers at Google Brain trained a robot arm to grasp objects with only visual input guided by a RGB camera feed. Using off-policy Q-learning, they found that they required about 800 hours (over 580k grasp attempts) of training data to achieve good performance4. The arm used was also much less complex than a human hand, which shrinks the action space substantially.

Flo can do better than this. Image from Google.
If we tried to get Florence to solve the cart pole problem (using a joystick or inputs from her eyes) it would probably take her far more than 500 tries. To her, grasping is much easier than cart pole. For computers, it is the opposite.
I’m also skeptical of a pure-RL hypothesis because it seems like babies can generalize much better than any AI system that I’ve encountered. Florence spends most of her time grabbing little toys on the rails of her bouncer (pictured above). If you hand her a new toy in a new place, though, she doesn’t need to start from scratch. This also means that Florence’s advantage isn’t just scale (number of neurons). If this were the case, you’d expect to observe overfitting and poor generalization. In fact, the opposite is true.
Some of Florence’s behavior is purely instinctual. When I put my finger in her hand, she grasps it reflexively. The purpose of the grasp reflex is not well known. It may be purely vestigial from our monkey days of tree-swinging, or it could serve some purpose in the development of voluntary grasping5. Regardless, it’s clearly not voluntary grasping. Based on reaction time, the grasp reflex happens at the spinal cord level5.
When I see Florence grab something on purpose, something very different from her reflexes is going on. It’s slow and deliberate. Often, she pauses to think about the situation or observe her environment. She is also getting better at it. She started by flailing her hands, eventually brought them near her toys, and finally started figuring out how to open and close her fists. It seems less like she is revealing latent knowledge and more like her skills are developing over time.

It’s also noteworthy to observe that children with amputated or anomalous limbs typically reach milestones like grabbing around the same time as unaffected children6. If children were hard-wired to grab things in the typical way, wouldn’t children with atypical arms and hands learn to do so more slowly?
Dwarkesh: Kids will initially learn from imitation. You don’t think so?
Sutton: No, of course not.
I agree with Sutton here. Florence is obviously not imitating me or Jackie. It’s not clear if she even understands that there’s a direct mapping between my hands and hers. Even if she does understand this, we are not usually attempting to perform the same tasks. Florence has seen me pick up a laptop more times than a rattle, and yet I trust her with the rattle, and not the laptop. Florence is developing her skills on her own time, regardless of what behavior I’m showing her.
In the typical cop-out way, I’m going to hypothesize that the answer is somewhere in between these options. Specifically, I think grasping is built on top of hard-wired behavior and understanding, and “fine tuned” with RL (I do not think imitation is meaningfully involved). But why do I feel confident writing this at all? I’m not a developmental scientist or psychologist, and my observations (n=1) are not significant. I know very little about children even compared to the average parent.
Even so, I think that if my model for what’s going on is false, it can still inform our attempts to train machines to do tasks like this. So here’s what I think.
I think that Florence is performing model-based RL, and she was born with no idea how to grasp, but the RL is assisted by some hard-coded aspects of her mind.
I think that Florence was born with a model of the world already in her head, which she uses to predict the consequences of her actions. The world model is much simpler than our actual world, but it’s complex enough to inform the basic task of grasping. It tells Florence that she lives in 3-dimensional space, she can observe it with her eyes, some objects are in front of others, eye parallax indicates distance, etc.

Where did the model come from? I think it was programmed by evolution. In the BERT metaphor, evolution is pretraining, and as organisms became more complex, so did their hard-coded understanding of the world. Certain animals clearly have hard-coded behavior at birth, like zebras, who can stand up 15 minutes after they’re born, and run inside an hour. In this case, the RL-instinct continuum is heavily weighted in favor of instinct, and yet you can still see a baby zebra’s trial and error in their very first steps. They just converge really quickly to doing things the right way.
I’m convinced that this world model exists because I watch the way Florence tries new tasks, and it clearly involves planning and anticipation. She looks at her hand, then she looks at the object, then she tries to grab it. Florence does not have enough experience to plan actions like this in a model-free way, so there must be a model. And I don’t think it’s learned from scratch because it’s too good. Many early-infant researchers seem to agree, arguing that infants have innate “intuitive physics” which allows them to predict that objects will fall under gravity, for example7.
I think that these basic facts about how the world works are 90% of what the computer is learning during Google’s camera-guided robot arm task. The remainder, “actually doing” the task, is much simpler once the agent infers the rules of the environment. It reminds me of how language models like BERT can be fine-tuned to perform many different language tasks by adding a task head to a pretrained model and training the task head alone. This works even though the pretraining is performed on largely unrelated tasks. Even in model-free methods, an RL agent still must learn a representation of the environment’s rules, it’s just hidden in the weights.
If you believe this, how should that change the way you plan and build intelligent systems?
First, I think it should temper your expectations of RL’s convergence speed. Yes, it should be possible to create a RL-based system which can manipulate real-world objects like a human, but even with a perfect algorithm and sufficient hardware, it may take longer. An infant and a randomly initialized neural network are not on an even playing field, and most of the learning necessary to interact with the world was done before the baby was born.
Put differently, just because RL takes a long time doesn’t mean it’s not working.
Second, I think this should spark our ambition to pretrain models with RL. On the podcast, Sutton says:
We’re not seeing transfer anywhere. Critical to good performance is that you can generalize well from one state to another state. We don’t have any methods that are good at that.
But such methods should exist! If we are born with a pretrained brain that helps us with many different tasks, we should be able to pretrain a model with RL most of the way to performing well on many tasks, and adapt it to specific tasks with only minor fine tuning. I think we should ambitiously chase RL algorithms which can generalize, or transfer, well.
van Duinen, Hiske, and Simon C Gandevia. “Constraints for control of the human hand.” The Journal of physiology vol. 589,Pt 23 (2011): 5583-93. doi:10.1113/jphysiol.2011.217810 ↩
Notes on the Resolution and Other Details of the Human Eye ↩
This is an overestimate, since the resolution in the fovea is much higher than the rest of the eye. Still, it’s likely within an order of magnitude or two. ↩
Kalashnikov et al. “Scalable deep reinforcement learning for vision-based robotic manipulation.” Conference on robot learning. PMLR, 2018. ↩
Falkson SR, Bordoni B. Grasp Reflex. [Updated 2025 Jan 22]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan-. ↩ ↩2
Edelstein and Denninger. Orthotics and Prosthetics in Rehabilitation (Fourth Edition). 2020, Pages 738-758 ↩
Hespos, Susan J, and Kristy vanMarle. “Physics for infants: characterizing the origins of knowledge about objects, substances, and number.” Wiley interdisciplinary reviews. Cognitive science vol. 3,1 (2012): 19-27. doi:10.1002/wcs.157 ↩